SUMMARY
This is AI generated summarization, which may have errors. For context, always refer to the full article.

CEBU, Philippines – 20 trillion gigabytes. That’s a number that’s almost incomprehensible to an individual. 500 gigabytes, 1 terabyte, 2 terabytes – these are still still pretty easy to translate to more human terms, usually converted to an equivalent number of movies or song files.
But 20 trillion gigabytes? That’s a little harder to imagine. There might not be enough individual movies created in human history to fill up a hard drive that size.
Of course, there is no hard drive that size. But there is what we call a digital universe, which is simply all the data that humans have created, copied, and made accessible digitally. And by 2020, this digital universe will by 20 trillion gigabytes large, according to IT tech leaders at the MSI-ECS Philippines’ CXO Innovation Summit, an enterprise tech convention held in Cebu on November 9 and 10.
Somehow, the world – both individuals and corporations – will have to find a way to manage that.
For enterprise tech solution providers, it’s a crucial area that’s shaping the solutions they’re attempting to offer. It’s also something that they believe should not be left unattended by client businesses, big or small. Just learning to manage data efficiently and rolling out solutions to intelligently process and manage all the information coming from all sides are key pillars to digital transformation.
More data coming
Why should enterprises adopt better data management practices and solutions? Because the data explosion isn’t over and is expected to continue to grow exponentially.
One avenue from which more data will be coming is smart cities. These are cities that use an array of connected sensors within the city for various beneficial purposes. Presenting at the summit, Zdravka Newman of network solutions firm Cisco, discussed digitally transforming traditional cities into a smart one.

The process is going to involve a whole lot of interconnectivity at the many interaction points between people and objects within the city, and it’s going to involve a lot of sensors. Light posts, for instance, will be able to detect when a person is in the area, thus automatically increasing the brightness of its lamp, and then turning it down again when there are no persons in the area. A system like this, says Newman, will generate significant savings for the city.
At the same time, it’s going to generate more data. How many people pass by the area at a specific time? How can this data then be leveraged for future city planning and strategies? Traffic lights can be equipped with sensors detecting vehicle traffic density. At some areas, sensors can detect water pollution or air pollution levels. As Newman demonstrated at the event, even trash bins may be outfitted with sensors to see where they’re filling up fast – data that the city can then use to better manage their deployment of garbage trucks.
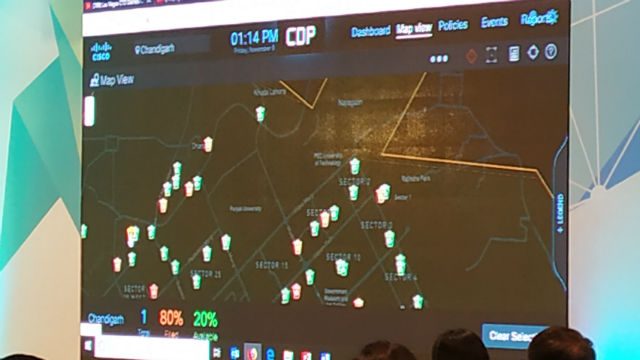
The short of it is that smart cities will be gathering a lot of data. And for Newman, one way that this influx can be managed is through standardization. She says that currently there is mix of communication products and companies are developing a lot of siloed technologies which may often only work with products within a brand. She describes that this is a “fragmented” approach that doesn’t lead to information sharing and leads to duplication in technologies and investment.
In a siloed environment, processes aren’t streamlined, requiring extra steps and time – time that could have been saved.
So instead of the siloed approach, Newman proposes aggregation, a system where all the information comes to one place, where all the various devices and sensors can be integrated into a network that work seamlessly with one another. Using Jaipur as an example, in which Cisco has been helping in establishing it as a smart city, Newman demonstrates a user interface showing a central hub where an administrator receives all the data from the city sensors, and is able to manage nearly everything from the strength of the light coming from a posts to alerting trucks of filled garbage bins.
Aggregation is one strategy, with smart cities being an example, that can help any administrator — whether it be a city administrator or an IT manager – better manage the flood of data.
Securing the data
As the digital universe grows, so does the pot of gold that hackers can dip their fingers in. The more data there is, the more data that can be stolen – data that, in a myriad of ways, have a real dollar value.
How much is data worth? Tarun Gupta, a regional solutions architect at cybersecurity firm Trend Micro, said at the convention that this dollar value is pretty huge.
Worldwide, the average cost of a breach now for large businesses is $4 million, Gupta said. Large consumer-facing businesses have a large database of users, hence, more data to steal and monetize for the hackers, with one recent big attack trend being ransomware.
Ransomware is akin to kidnapping a person only to be returned according to the terms of the attacker – only in this case, it’s valuable, crucial data that’s being held in captivity.
Managing ransomware attacks and other types of hacking is only going to get more complex in the coming years.
First, the inter-conected internet-of-things (IOT), which encompasses every object able to connect to a network and to one another will be generating and collecting more data. There are more entry points for the attackers, whether you’re an individual or a company.
Second, the speed at which attacks are detected needs to ideally “be as fast as possible,” Gupta said. But currently, the average number of days before an attack is detected is 99 days. It’s not fast enough. And because of that, Gupta emphasizes detection in their strategies, and that companies should invest in better, faster detection measures. The faster that an attack can be detected, the more that the potential damage is limit, and the faster that an appropriate counter-response can be deployed.

It’s a tug-of-war though, the expert said: hackers find a way to be sneakier as cybersecurity firms sharpen their noses.
One way that their sharpening their detection skills in this data age is with artificial intelligence (AI) – just as many other companies in other verticals are attempting to speed up data processing with AI. It’s actually somewhat ironic. As people generate and put more data online, which could be targeted by hackers, AI and machine learning themselves are relying on a ton of data, from which it learns how to spot certain behavior signals.
Gupta demonstrated this through their AI-powered malware detection system for email, which is able to identify malicious email that seems to have been sent by a real person within a company. Studying the writing style of a person, the AI is able to spot the tiny differences in writing style between the legitimate email and the fake email, eventually flagging the fake one. From the point-of-view of a person, the two emails look exactly the same, but through AI-equipped technologies, the littlest differences can be spotted.
The demonstration reiterated AI’s importance in helping speed up data processing – in this case, a cybersecurity scenario for processing and identifying which data is legitimate, and which is harmful. Imagine if a real person had to manually check an email for style inconsistencies. It’s going to cost consumer manpower and time, and will not be able to keep up with the amount of data flow today.
Echoing sentiments
AI is just one way that technology can help data management today. There are other ways. For example, IBM Philippines’ chief technologist Lope Doromal Jr. also showed how blockchain and its potential to be a secure, trustworthy data-keeping tool can feed us more valuable, more trustworthy data faster.
Blockchain, because of its immutability, can hold much more authentic data, and this frees people from the extra process of determining the trustworthiness of a certain piece of data.
Instead of having to swim in a sea of data, a blockchain can be set up to track, say, diamonds. The blockchain will be able to tell and record where each diamond comes from, potentially decreasing the chance that a person will buy a “blood diamond” from conflict areas. Immediately, a buyer has a way to know right away that the product they are buying is legitimate, making the purchase process faster. IBM has one such product doing this, called IBM TradeLens, for shipment tracking.
In agriculture and health, Doromal showed another example, IBM Food Trust, in which a blockchain can be set up to track where each delivery of a product comes from. This way, in case a contaminated product causes health problems, officials will be able to find the product’s origin data faster. Instead of having to temporarily ban all the shipments of a product – spinach, for example – because of the health scare, officials can find the specific deliveries that caused harm and just ban those deliveries.

But even with all this fancy-sounding technology helping people manage data, what the executives agree on is that the human being’s role in all this will not be completely replaced. “The AI is not going to replace the human being. It’s just going to do things faster,” says Tan Kwong Hui, regional category manager at wireless networking firm HPE Aruba.
But there will have to be some change in how IT professionals should be deployed said Jay Tuseth, APAC chief strategy officer at Dell, noting that they should be slowly deployed more in ways they can develop competitive advantage as opposed to just “keeping the lights on,” which can be automated anyway.
A healthy mix of tech and human agency appear to be the general strategy in containing the data explosion that the information age has brought. – Rappler.com
Add a comment
How does this make you feel?
There are no comments yet. Add your comment to start the conversation.